
1.はじめに
McKinsey の調査によると、知識労働者は業務時間の 約 19〜20% を情報の検索や収集に費やしているとされています。『検索』のなかでも、例えば「経費申請のやり方」や「自社開発システムの使い方」といった会社特有の情報については、当然ながらインターネット検索で入手することができません。
弊社では「経費申請のやり方」も「自社開発システムの使い方」もドキュメント化されて全社員が閲覧できる状態にはなっていますが、各ドキュメントの保管場所が「ファイルサーバ」「社内ポータルA」「社内ポータルB」といったようにバラバラであり、「まずどこを探せばいいのか?」というところにハードルがある状態となっていました。また、ファイルサーバも社内ポータルも検索性が低く、どこにドキュメントがあるかが分かってもなお目的のドキュメントにたどり着くまでに時間がかかるという問題もありました。
これらの課題を解決するため、生成AIを活用した社内文書検索の仕組みを構築するプロジェクトに挑戦しました。
2.構成
今回のプロジェクトでは、Googleが提供するVertex AIのAPIを活用し、Google Apps Script(GAS)で社内文書検索アプリ"ザイブラリ"を構築しました。
Vertex AIでは、自然言語処理と生成AIの高度な機能を手軽に利用可能で、GUI上で各種パラメータをカスタマイズすることが可能です。また、他のGoogle Cloud Platform(GCP)との連携がスムーズで、すでに社内で活用していたGoogle Workspaceとシームレスに統合することも可能です。Vertex AI Agent Builderではスモールスタートに適したウィジェットが提供されていますが、Vertex AIのAPIとGASを組み合わせることで、より高機能でかゆいところにも手が届くアプリを構築しました。
全体の構成図は以下のようになっています。
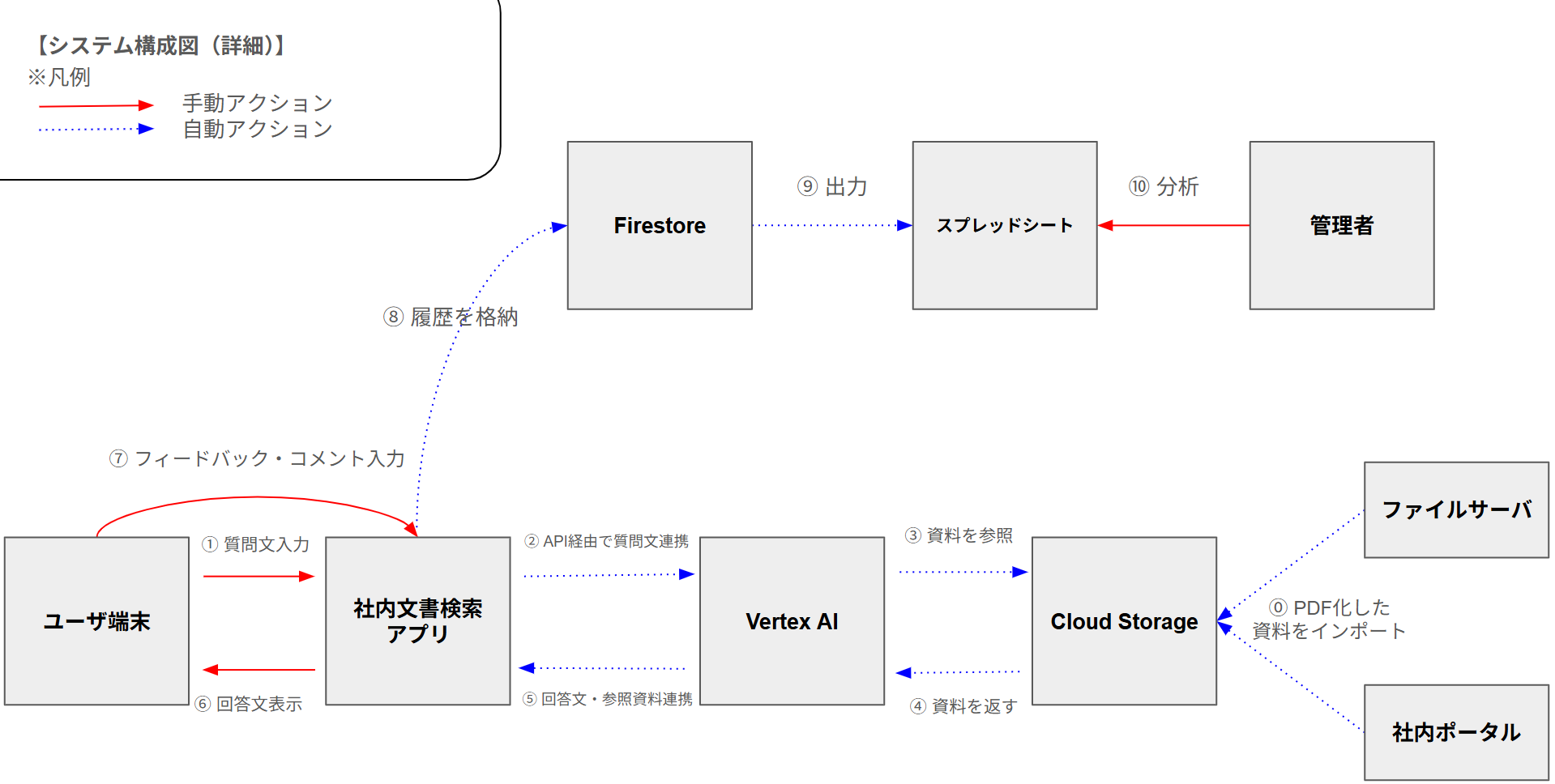
まず、ファイルサーバや社内ポータルのドキュメントをPDFファイルに変換してCloudStorageに格納し、AIが参照するRAGを準備しました。ドキュメントは日々更新・追加・削除されるので、常に最新の情報を検索できるようにするためにはCloudStorageの情報も毎日リフレッシュする必要がありますが、この作業を手動でおこなっていては大変なので、別途自動化ツールを作成しました。
さらに、Vertex AIの環境を用意し、CloudStorageに保管したPDFファイルをデータストア化しました。これによって、Vertex AIで特定のドキュメントを参照したRAGをおこなえるようになりました。
Vertex AI側の準備は完了したので、次にアプリケーションを作っていきます。検索アプリのフロントエンドはGASとHTMLをベースにしながら、Reactを組み合わせて動的かつ柔軟なUIを実現しました。
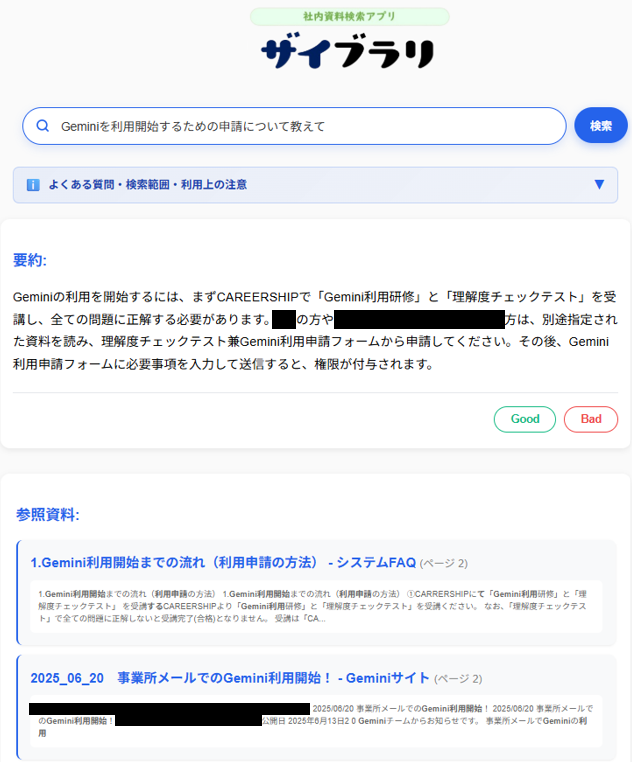
"ザイブラリ"は「質問文入力欄」「要約文表示欄」「参照資料表示欄」「フィードバック欄」とそれに付随する注意事項のアコーディオンなどから構成されています。
ユーザが質問文を入力して検索すると、社内資料をもとに要約が生成されます。複数の資料にまたがっているような質問でも、この要約を読むことで概要を把握することができます。ただし、生成AIを用いているのでハルシネーションを100%避けることはできません。そのため、要約の生成に用いた資料も表示されるようにしており、ユーザには一次ソースである参照資料を確認するように呼びかけています。
また、フィードバック欄も設けています。ユーザが要約に違和感を覚えた場合や、資料が出てこなかった場合など、フィードバックしてもらうことで管理者側も問題点を把握しやすくなります。フィードバックデータはFirestoreに格納されるように設定しており、そのデータを分析することで、効率的にLLMのプロンプトの調整や資料の修正などをおこなうことができます。
3.まとめ
今回はGoogleのVertex AIとGoogle Apps Scriptで構築した社内文書検索アプリについてご紹介しました。各種Google Cloud Platformを組み合わせることで、生成AIに対しての深い知見がなくても、生成AIを用いた社内文書検索アプリを構築することができました。
ここまでお読みいただきありがとうございました。