0.はじめに
2024年10月15日から12月13日にかけて開催された、SIGNATEの「第1回 国土交通省 地理空間情報データチャレンジ ~国土数値情報編~」に参加しました。
このような分析コンペには2回目の参加で、528人中63位でした。
本記事では、主に分析コンペ初心者の方に向け、使用したアプローチや得られた知見などをご紹介します。
1. コンペ概要
SIGNATEとは
SIGNATEはデータ分析コンペを開催しているプラットフォームです。参加者は与えられたデータからモデルを構築し、様々な指標で競い合います。
今回の課題
- 住宅物件の賃料予測モデルを構築
- 国土数値情報の利用が必須
- 一部の民間企業データ(ZENRIN など)も利用可(その他の外部データは不可)
- 評価指標は RMSE(Root Mean Squared Error)
- RMSEとは、差の二乗の平均を取った値の平方根です。二乗平均ですので、予測を大きく外すレコードがあると強く影響を受けます。
- ちなみに、絶対値の平均であるMAE(Mean Absolute Error)もしばしば使われます。
データ
- LIFULLポータル上に掲載されていた賃貸マンション/アパートの物件データ
- train:約58万行(2019~2021年分)
- test:約30万行(2022~2023年分)
- 暫定評価と最終評価の分割方法は公開されていません。
- 各物件に対して掲載当時に登録されていたデータがすべて入っており、カラム数は約150列。ただし重複している項目も多いです。
- 参考:過去に東京23区で同様の賃料予測コンペも開催されています(こちら)。
2. 使用モデル:GBDT と LightGBM
今回は、GBDTの一種であるLightGBMというモデルを使用しました。
GBDT(勾配ブースティング木)
決定木を作成した後、その誤差を補正する木を段階的に追加していく手法です。計算速度が比較的速く、外れ値やノイズに比較的強いという特徴があります。LightGBM以外によく用いられるものとしては、XGBoostやCatBoostがあります。
LightGBM(LGBM)
GBDTのアルゴリズムの1つで、計算速度が非常に速く、欠損値をそのまま処理できます。
以上のような特徴から、雑にデータを投げてもそれなりの精度を出せることが多く、初手のモデルとしてよく使われます。
今回も最初に LGBM を試したところ、データ数が多いこともあり1回の予測に30分程度かかりました。そのため他のモデルではさらに時間がかかりすぎて試行回数が減ると考え、そのままLGBMをベースとして使用することにしました。
3. 前処理
文字列変数の変換(encoding)
文字列は、そのままではLGBMモデルの予測に利用できないため、何らかの手法で整数値に置き換える必要があります。これをencodingといい、いくつかの手法があります。
今回は、簡単な方法として以下のようにしました。
カテゴリ変数は基本的に label encoding
カテゴリ名を適当な整数に置き換える手法。
例:北海道 → 1、青森 → 2、岩手 → 3...
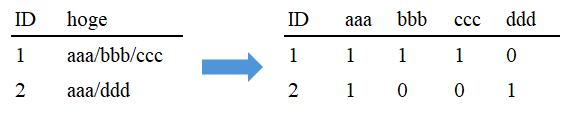
スラッシュ区切りで複数の値が入っている列は one-hot encoding
カテゴリの種類ごとに新たな列を作成し、1か0を割り当てる手法。
例
encodingはほかにもいくつかの手法があるので、興味がある方は調べてみてください。
面積単価への変換
過去の東京23区での同様のコンペにおいて、入賞者の複数が賃料を面積単価に変換して予測していました。
そのため、今回も賃料を「面積単価(賃料 / 面積)」に変換して予測を行いました。
外れ値の対処
各変数に多くの外れ値が見られました(面積が1m^2の物件 、逆に 1000m^2 超えの物件、賃料が月3億円の物件 etc)。
面積と賃料は極めて重要な変数と考えられます。そこで適当な範囲を決め、それを超えるものは欠損値に変換する方針としました。
例:東京都内の物件は面積単価500~20,000円、その他地域は500~10,000円など。
パーセンテージや四分位数に基づいてカットする手法も主流ですが、本コンペでは「ごくわずかに超高級物件が含まれ、それらの予測を外したくない」という考えから、このような緩やかなクリッピング(欠損化)をしました。
終盤に面積以外の変数も同様にざっくり処理しました。
欠損値の補完
各説明変数にも多くの欠損がありました。面積については LightGBM(LGBM)で予測し、補完を行った結果、スコアが大きく向上しました。
終盤で他の変数も同様に補完を試みましたが、スコアはほぼ変わりませんでした。
4. クロスバリデーション(CV)の工夫
k-fold CV の基本
- データを k 個に分割
- 1つをバリデーション (val)、残りをトレーニング (train) として学習
- これを k 個全てで繰り返し、スコアの平均を取る
- テストデータへの予測方法は
- k 個のモデルの予測結果を平均する
- 全データで再度トレーニングしたモデルを使う
時系列データでの注意点
一般には、未来を予測する際に、train を過去データ、val を未来データとするなど、時間を考慮した分割が必要です。
しかし今回は、年度による賃料への影響は確認できなかったため、ランダムな CV としました。
5. 外部データの活用
国土数値情報
必須利用となっている国土数値情報の中で、以下を採用しました。
- 地価公示データ(周囲の公示地価平均)
- 人口推計情報
- 人口集中地区関連情報
- 近隣駅の乗降客数
ZENRIN API
ZENRIN APIを利用し、物件が立地する道路の路線価を特徴量に加えました。
- 相続税路線価(最近傍の値)
6. 特徴量選択
LIFULLデータには住宅性能評価書や各種証明書の有無など、賃料に影響がなさそうな項目もかなり多くありました。そのため、LGBMの特徴量重要度が下位のものについて、精度が悪化するまで順次削除していきました。
最終的には約150個の中から、約80個の特徴量が残りました。削減による精度向上は見られなかったものの、計算時間は半分ほどになりました。
7. トレインデータとテストデータの重複について
建物単位で見ると、テストデータの約半分において、同じ建物の物件(=部屋)がトレインデータにも含まれていました。物件単位では、数千件程度が重複していました。
建物単位の処理
building_id を説明変数に加えるだけに留めました。
同じ建物の賃料で上書きしたり、建物ごとの Ridge 回帰モデルを作ったりも試しましたが、スコアは下がったので採用しませんでした。後者は別のコンペでの上位解法を参考にしましたが、やり方がまずかった可能性もあります。
物件単位の処理
物件単位でトレインと同一のものがあった場合、その賃料を上書きしたところ、スコアが向上しました。
8. パラメータ関連
LightGBMには様々なパラメータがありますが、特に影響の大きい2つについて以下で紹介します。その他については、optunaライブラリを用いてチューニングしました(興味のある方は調べてみてください)。
metrics
RMSE では外れ値の影響が大きく、学習が安定しない可能性が考えられたため、MAE(平均絶対誤差)をメトリクスに使う方法も試しました。
しかし、計算時間が伸びたにも関わらず、精度に変化が見られなかったため却下しました(上位解法ではMAEを使用した例もあり、手法次第なようです...)。
boosting type
LGBMのパラメータには、gbdtやdartなどのboosting typeがあります。
基本的にはgbdtが最も計算時間と精度のバランスが良く、一般に使用されています。
dartは、計算時間が大幅に長くなる代わりに、精度が少し高くなる傾向があります。
実際に試したところ、計算時間は約5倍かかったものの、スコアはわずかに上昇しました。
最終的には(おまじないとして)、 dart:gbdt = 7:3 程度で予測結果をアンサンブルして提出しました。
9. まとめ・感想
前回参加したSIGNATE CUPでは数千行のデータでしたが、今回は数十万行という大規模な実データを使ったコンペであり、とても面白い経験になりました。1回の CV スコア確認に30分以上かかることもあり、実験の質や効率が大事だと痛感しました。
当社業務においても、機械学習によって効率化を検討できる部分は多くあるはずです。
特に画像処理関係では、異常箇所の検知や検針の自動化など、色々な用途が考えられます。そのため、今後は画像コンペなどにもチャレンジしてみたいです。